Introduction to Ensemble Learning¶
Info
Author: Tina, Published on June 6th, 2021, Reading Time: Approximately 6 Minutes, WeChat Official Account Article Link:
1 Introduction¶
Ensemble Learning is a common and important concept in machine learning, which refers to completing learning tasks by building multiple machine learners. Today, we will introduce some common methods of Ensemble Learning, such as Voting Classifiers, Bagging, and Boosting.
2 Ensemble Methods¶
2.1 Voting Classifiers¶
As shown in the figure below, the basic principle of Voting Classifiers is based on the same training set, using different model algorithms to fit the data, and then aggregating the final results to obtain the final result.
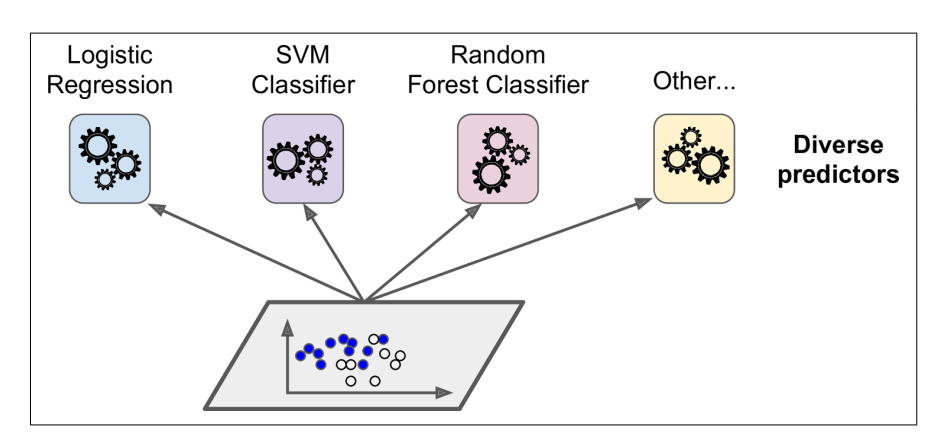
Its code implementation is shown as follows:
## RandomForest, Logistic Regression and SVC
## participate in ensemble learning
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression()
rnd_clf = RandomForestClassifier()
svm_clf = SVC()
##aggregate three algorithms as Voting Classifier
voting_clf = VotingClassifier(
estimators=[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf )],
voting= 'hard'
)
voting_clf.fit(X_tran,y_train)
After the training is completed, you can view the performance of each classifier on the test set:
## Look at each classifier's accuracy on the test set:
from sklearn.metrics import accuracy_score
for clf in (log_cf,rnd_clf,svm_clf,voting_clf):
y_pred = clf.predict(X_test)
print(clf.__class__.name__,accuracy_score(y_test,y_pred))
#### Output:
### LogisticRegression 0.864
### RandomForestClassifier 0.872
### SVC 0.888
### VotingClassifier 0.896
It should be noted that the ensemble classifier may not perform well in all cases. For example, when the majority of "weak learners" make up the ensemble classifier and the model with good performance make up the minority, the performance of the Ensemble Learning may not be as good as that of a single classifier when taking the "major votes" as the prediction result.
2.2 Bagging and Pasting¶
Ensemble Learning can also be implemented by fitting different sub-datasets with the same model algorithm.
Bagging (bootstrapping aggregating) means sampling with replacement, while pasting means sampling without replacement. As shown in the figure below, Ensemble Learning can obtain multiple prediction results through multiple sampling, and then combine all the results together. Generally, the maximum frequency prediction value or the average value is selected as the final learning result.
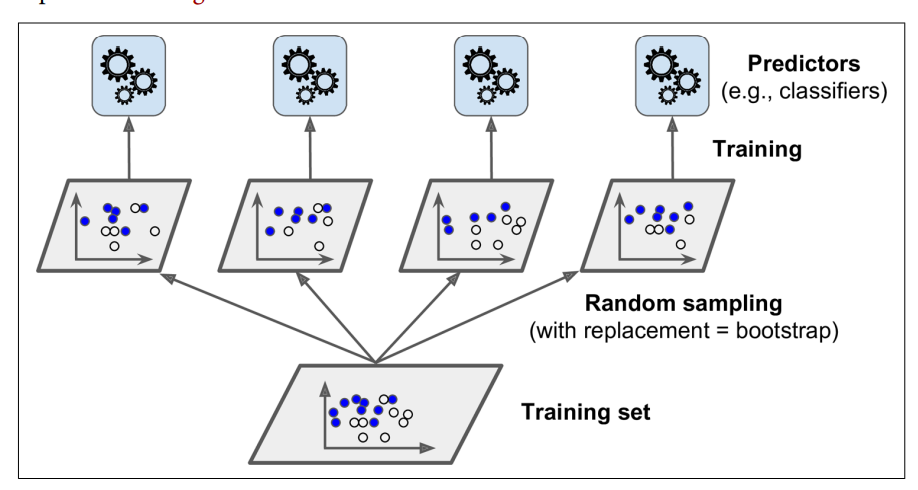
Its code implementation is shown as follows:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
## with 500 trees, n_jobs = -1
## means using all processors
##to fit and predict in parallel.
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1
)
bag_clf.fit(X_train,y_pred)
y_pred = bag_clf.predict(X_test)
In bagging, there may be situations where the data is fitted by multiple classifiers at the same time. Then there will be some data that has not been trained, which is the out-of-bag (OOB) part of the data. This part of data is used to evaluate the performance of the model in the end.
In Scikit-Learn, you can directly set oob_score=True to achieve:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs = -1, oob_score = True
)
bag_clf.fit(X_train,y_pred)
bga_clf.oob_score_
###0.93066666666664
### To verify by accuracy score on test set
from sklearn.metrics import accuracy_score
y_pred = bag_clf(X_test)
accuracy_score(y_test,y_pred)
###0.936000000000005
2.3 Boosting¶
Boosting is a way of combining multiple "weak learners" into an ensemble model. Unlike the previous methods, Boosting trains classifiers in sequence and corrects the previous classifiers' misclassifications in each iteration. The most common methods include Adaptive Boosting (AdaBoost) and Gradient Boosting.
2.3.1 AdaBoost¶
During the evolution of the classifier in AdaBoost, more attention is paid to training the under-fitted data set. As shown in the figure below, when building such classifiers, the subsequent classifiers continually learn and update the weights of the previous classifiers during training to improve the fitting effect of the data.
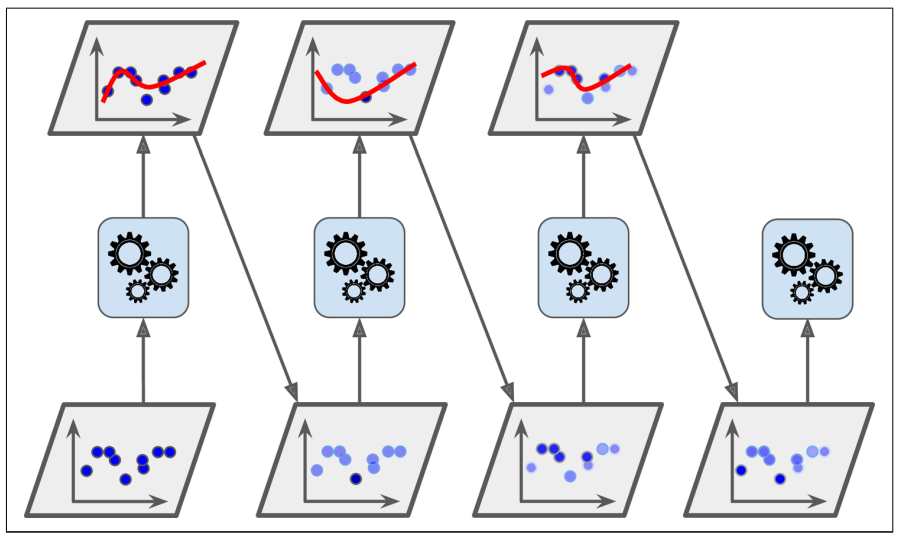
Its code implementation is shown as follows:
from sklearn.ensemble import AdaBoostClassifier
## 200 decision stumps with 0.5 learning rate using the
## Stagewise Additive Modeling Multiclass Exponential loss function
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth =1),n_estimator = 200,
algorithm = "SAMME.R",learning_rate =0.5
)
ada_clf.fit(X_train,y_train)
n_estimator, overfitting of AdaBoost Ensemble can be controlled. 2.3.2 Gradient Boosting¶
Like AdaBoosting, Gradient Boosting also learns data sets in sequence to continuously iterate to generate a robust ensemble model. However, the difference is that Gradient Boosting fits new data to reduce the residual error of the previous classifier, rather than updating the weight of previous classifiers.
We can take Gradient Boosted Regression Trees(GBRT) as an example to learn the implementation method of the code:
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X,y)
### residual errors
y2 = y-tree_reg1.predict(X)
## Train the second regressor on residual errors made by the first one
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X,y2)
## Train the third regressor on the residual errors made by the second one
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)
## The ensemble model contains three trees, it can make predictions on a
## new instance by adding up the predictions of all trees
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2,tree_reg3))
We can also directly use the method of GradientBoostingRegressor to achieve the above effect:
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth = 2,n_estimators = 3, learning_rate=1.0)
gbrt.fit(X,y)
To find the best