Kaggle Jane Street Competition¶
Info
Author: Void, posted on September 2, 2021, Read time: About 10 minutes, WeChat Official Account Article Link:
1 Introduction¶
There are many hedge fund-sponsored competitions on Kaggle, which may have become a new type of competition, or they may really want to get some ideas from Kaggler.
This time, we will learn about the recently completed Jane Street-sponsored competition.
2 Competition Introduction¶
This competition is a classification problem. For each data point (a trading opportunity), we need to give an action (whether to take action). If we execute the trade, the corresponding profit is return * weight, added up to each day:
In the investment field, many people pursue a high Sharpe ratio (considering both returns and risks). Its calculation is as follows:
Our final evaluation metric is:
3 Specific Code¶
Similarly, let's take a look at the open-source high-scoring code together.
3.1 Import Packages¶
As the dataset is large, the code uses datatable to perform data reading, which claims to be a highly efficient multi-threaded data processing tool that outperforms Pandas.
import datatable as dtable
train = dtable.fread('/kaggle/input/jane-street-market-prediction/train.csv').to_pandas()
3.2 Feature Engineering¶
As the provided features are still anonymous, the code artificially divides the features into four types based on the distribution of each feature: Linear, Noisy, Negative, and Hybrid.
The final feature is constructed by adding the mean of each class of features to all the original features.
train['f_Linear']=train[f_Linear].mean(axis=1)
train['f_Noisy']=train[f_Noisy].mean(axis=1)
train['f_Negative']=train[f_Negative].mean(axis=1)
train['f_Hybrid']=train[f_Hybrid].mean(axis=1)
3.3 Label Determination¶
The training set does not provide us with direct labels, i.e., whether to take action. It provides the returns for five different time windows. The code constructs the label by determining whether there are greater than three positive returns, i.e., executing trades (action = 1).
resp_cols = ['resp', 'resp_1', 'resp_2', 'resp_3', 'resp_4']
y = np.stack([(train[c] > 0).astype('int') for c in resp_cols]).T
train['action'] = (y.mean(axis=1) > 0.5).astype('int')
3.4 Model Training¶
Regarding the model part, the solution uses an XGBoost model and performs parameter optimization using HyperOpt.
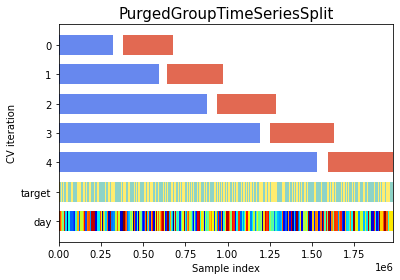
For cross-validation, it uses PurgedGroupTimeSeriesSplit, which is suitable for this type of time series problem. It can be seen very intuitively from the figure below. The validation set always comes after the training set, with a small gap in between.
4 Conclusion¶
It can be seen that this open-source solution is not complicated, and there is still a lot of room for improvement, such as analyzing the meaning of features, using neural network models, optimizing the evaluation metric given in the problem, and so on. However, in the financially noisy world, whether these methods are effective is still a question mark.