Building Tree Models with TensorFlow Decision Forests¶
Info
Author: Vincent, Published: 2021-06-06, Time: About 6 minutes read, WeChat article link:
1 Introduction¶
Both deep learning and traditional machine learning have excellent frameworks in their respective fields. For example, when building neural networks, TensorFlow and PyTorch are the common choices. The traditional tree model still performs very well in dealing with tabular data in real work. However, for a long time, deep learning frameworks did not have APIs to build tree models, until the emergence of TensorFlow Decision Forests.
TensorFlow Decision Forests provides a series of APIs to build tree-based models, such as Classification and Regression Trees (CART), Random Forest, Gradient Boosted Trees, etc. With TensorFlow Decision Forests, we can construct tree models using a paradigm similar to building neural networks. This article will explore it!
2 Obtain Data¶
As usual, import dependencies and download data. We use a tabular dataset to predict the species of penguins.
import tensorflow_decision_forests as tfdf
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import math
# Download the dataset
!wget -q https://storage.googleapis.com/download.tensorflow.org/data/palmer_penguins/penguins.csv -O /tmp/penguins.csv
# Load a dataset into a Pandas Dataframe.
dataset_df = pd.read_csv("/tmp/penguins.csv")
# Display the first 3 examples.
dataset_df.head(3)
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | male | 2007 |
| Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | female | 2007 |
| Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | female | 2007 |
Specify the label field and convert the label category to integer data.
label = "species"
classes = dataset_df[label].unique().tolist()
print(f"Label classes: {classes}")
dataset_df[label] = dataset_df[label].map(classes.index)
3 Split and Process Data¶
Split the data into training set and test set:
def split_dataset(dataset, test_ratio=0.30):
"""Splits a panda dataframe in two."""
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples for testing.".format(
len(train_ds_pd), len(test_ds_pd)))
Then convert the Pandas DataFrame to the TensorFlow Dataset, which makes it easier to simplify the subsequent program and improve efficiency.
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label)
Then data can be injected into the model for training. Unlike traditional machine learning frameworks, TensorFlow Decision Forests has the following advantages in implementing tree models:
- Automatically handles numeric and categorical variables, eliminating the need to encode categorical variables and normalize numeric variables. The algorithm can also handle missing data well!
- Hyperparameters are basically similar to those in other frameworks and default parameters give decent results in most cases.
- Before training, there is no need to compile the model, and there is no need for a validation set during training. The validation set is only used to display performance metrics.
Note that this does not mean that using TensorFlow Decision Forests can eliminate all feature engineering, but it does save a lot of time.
4 Modeling¶
Construction of a random forest:
# 构建随机森林
model = tfdf.keras.RandomForestModel()
# 训练模型
model.fit(x=train_ds)
# 评估模型
model.compile(metrics=["accuracy"])
evaluation = model.evaluate(test_ds, return_dict=True)
print()
for name, value in evaluation.items():
print(f"{name}: {value:.4f}")
Output:
1/1 [==============================] - 1s 706ms/step - loss: 0.0000e+00 - accuracy: 0.9608
loss: 0.0000
accuracy: 0.9608
5 Visualize Tree Model¶
TensorFlow Decision Forests provides a native API for visualizing trees. Here we select a tree from the forest for display.
with open("plot.html", "w") as f:
f.write(tfdf.model_plotter.plot_model(model, tree_idx=0, max_depth=3))
from IPython.display import IFrame
IFrame(src='./plot.html', width=700, height=600)
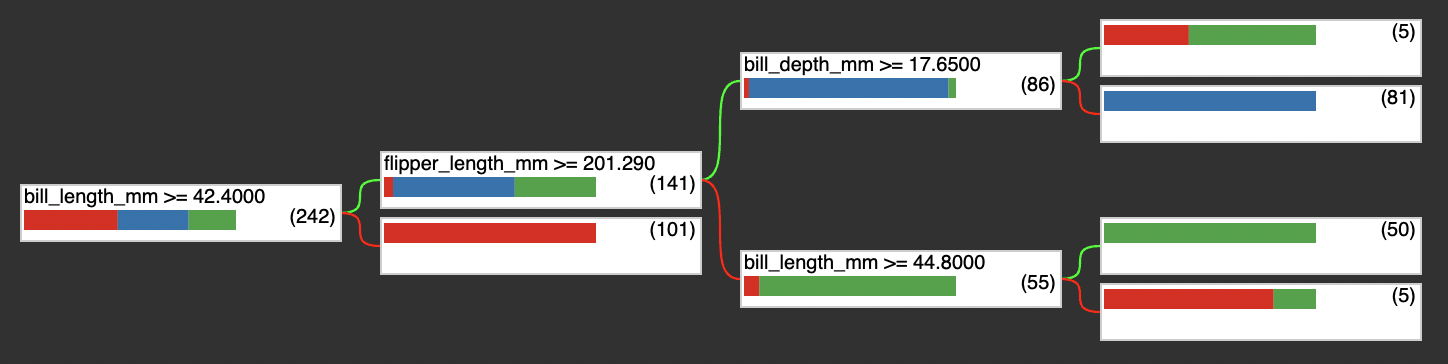
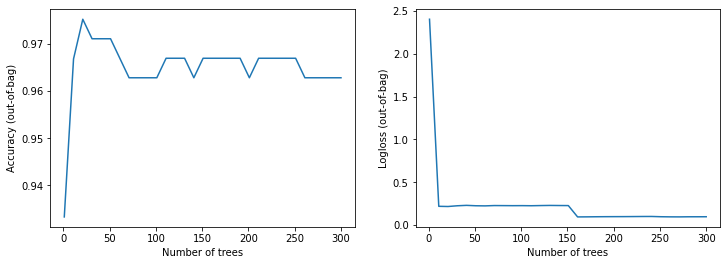
There's also a lot of useful information in model.summary(), such as input features, feature importance, node information, etc. (limited space, not elaborating one by one). During the training process, the accuracy and loss can also be visualized:
import matplotlib.pyplot as plt
logs = model.make_inspector().training_logs()
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy (out-of-bag)")
plt.subplot(1, 2, 2)
plt.plot([log.num_trees for log in logs], [log.evaluation.loss for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Logloss (out-of-bag)")
plt.show()
6 Conclusion¶
TensorFlow Decision Forests strengthens the TensorFlow ecosystem and provides new ideas for data scientists to model tabular data. It is still in its early stages (v0.2.3), but it already has many available high-quality APIs. More functionalities can be found in the documentations. Hope this sharing will help you in your work. Welcome to leave a comment for discussion!