TensorFlow Recommender System (Part 1)¶
Info
Author: Tina, Posted on December 10, 2021, Read Time: About 6 Minutes, WeChat Official Account Article Link:
1 Introduction¶
We often see a "For You" feature on various platforms, such as YouTube recommending videos you might like or music apps suggesting music you might enjoy. The principle behind this function is actually an artificial intelligence recommendation system. Today we will introduce the TensorFlow Recommenders (TFRS) library, which is used for building recommendation models.
For friends who are interested in TensorFlow, you can also review our related articles:
- Introduction to Various Keras Callbacks
- Custom Models with TensorFlow-Keras
- Installing TensorFlow on Apple Silicon Macs
- Reading "30 Days to Learn TensorFlow 2.0"
2 Recommendation Principle¶
We will use an example of a movie recommendation system to explain the principle of recommendation systems.
For the existing four users and five movies with different genres, we first need to create a user profile and define the movie categories. This step is to distinguish the data and convert real-world features into computable variables. For existing user and movie data, how do we recommend movies to user D that she might like?

As shown in the figure below, we create a two-dimensional matrix for each of the user and movie variables. For users, we will define whether they prefer children's movies (-1 means they like children's movies very much, and 1 means the opposite) and whether they prefer action movies (1 means they like action movies very much, and -1 means the opposite). For movies, we define whether they are children's movies (-1 means that they are children's movies, and 1 means the opposite) and whether they are action movies (1 means they are action movies, and -1 means the opposite).
It can be seen that User A likes to watch children's and action-packed movies, which is based on two dimensions of User Embedding; and "Shrek" is defined as a children's and action-packed movie, which is the process of Movie Embedding. It is worth mentioning that the dimensions of Embedding are not only two-dimensional, but often use multidimensional matrix to represent variables.

Next, we use matrix decomposition to perform collaborative filtering to calculate the feedback matrix of prediction. As shown in the figure below, U represents the user matrix, and V represents the matrix of candidate movie items. The computed A value is the predicted feedback value. Therefore, collaborative filtering is to recommend based on the similarity between users and candidate items.
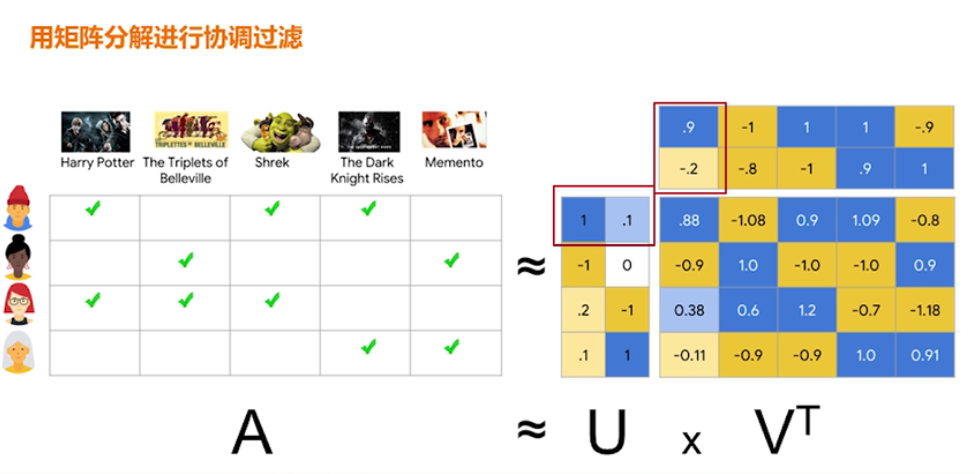
When using matrix decomposition to perform collaborative filtering, in order to reduce the prediction error of the objective function, two methods are used: stochastic gradient descent (SGD) or weighted alternating least squares (WALS).
It is worth mentioning that WALS is a new algorithm created specifically to solve recommendation systems, the idea of which is different from the former. During each iteration, WALS fixes the value of U to determine V and then fixes the value of V to determine U. Each method has its advantages and disadvantages, which we will not cover in detail here