The Multi-Family in Algorithms¶
Info
Author: Void, posted on 2021-10-10, Reading time: about 6 minutes, WeChat public account article link:
1 Introduction¶
In machine learning, there are some tasks of multi-X, such as multi-class, multi-label, multi-task, etc. Today, we will study the multi-family together.
2 Multi-Class Task¶
Multi-class task refers to each data having a label, but the label has multiple categories (more than 2). Compared with binary classification tasks, there is not much difference in multi-class tasks. It should be noted that the loss function changes from binary cross-entropy calculated by the sigmoid function in binary classification problems to multi-cross-entropy calculated by the softmax function.
The evaluation metrics of multi-class tasks are also different. The evaluation metrics of common binary classification problems are: Precision, Recall, and F1-score based on a 2-dimensional confusion matrix. For multi-class problems, these three evaluation metrics exist in two categories: micro and macro. In sklearn.metrics.f1_score, the average has the following parameters: {'micro', 'macro', 'samples', 'weighted', 'binary'} or None. For macro, we calculate the precision, recall, and F1-score of each category separately, and then take the average to obtain the final evaluation metric. To consider the imbalance of categories, we can add weights when averaging. For micro, we calculate the overall confusion matrix and then calculate the final evaluation metric.
3 Multi-Label Task¶
Multi-label task means that each data has multiple labels. For example, predicting whether a patient has multiple diseases. The simplest processing method is to treat it as multiple binary classification tasks. However, this is time-consuming and laborious, and there are often correlation relationships between multiple labels. The common practice is to still train in the same model (one loss). The processing method is to apply the sigmoid function to the output of the final classification layer (n nodes represent n labels), and then calculate binary cross-entropy separately and take the average. A more advanced method is to use sequence models or graph models, which can consider the dependency relationships between different labels.
4 Multi-Task Task¶
Multi-task learning means learning multiple tasks at the same time (there are multiple losses), such as predicting whether a user clicks and shares. Generally, multiple tasks are learned synchronously. Of course, asynchronous mode can also be used (more like pre-training, fine-tuning with task B based on task A).
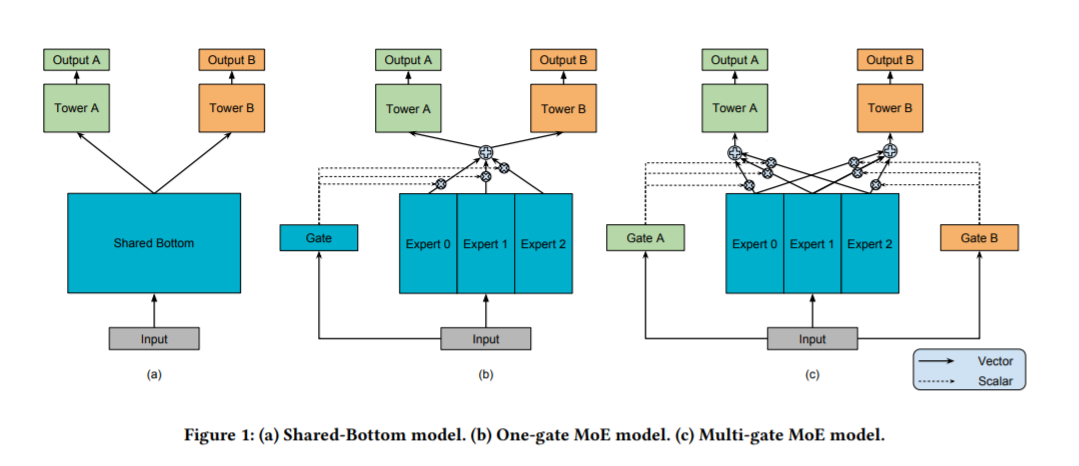
The common model structure of multi-task learning is shown in Figure (a), where the bottom layer parameters are completely shared, and the top layer parameters vary with different tasks. This method requires that the input variables of different tasks need to be consistent, which is often difficult to achieve (different tasks have their own unique features). Therefore, the structure of MMOE (Multi-gate Mixture-of-Experts) in © appears. It allows us to have both shared and unique parts, and their weights are determined by the gate through learning.
The benefits of multi-task learning may include the following:
- Alleviate the cold start problem, such as small amount of data for new tasks.
- Improve the robustness of the model. Different tasks often have different noises.
5 Conclusion¶
This article summarized the multi-family that often appears in machine learning tasks. Clarifying their concepts is beneficial to both physical and mental health, and can help you flexibly use different tasks to solve practical problems.