Introduction to PySpark¶
Info
Author: Void, published on September 20, 2021, reading time: about 10 minutes, WeChat official account article link:
1 Introduction¶
The Hadoop ecosystem is still a popular solution for storing data in many companies. Tools for operating this data include Hive (mainly for writing SQL), Pig (processing underlying data files directly, reading, filtering, concatenating, storing, etc.), and Spark. Spark is said to be faster and provides many libraries, such as SQL queries, streaming calculations, and machine learning. The appearance of PySpark allows us to run Spark tasks directly using Python API. With it, we can even abandon Pig, which has somewhat limited functionality. And we don't need to store the data as Hive tables before executing Hive SQL. This article will introduce related features and syntax from the PySpark documentation.
2 Introduction to PySpark¶
PySpark installation requires adaptation to the Hadoop version. After installation, we can start the Spark process with the following code.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Tabular data exists in PySpark in the form of a Spark DataFrame. We can directly create a DataFrame as follows.
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
We can also directly read the underlying data as a Spark DataFrame (commonly used). After obtaining the DataFrame, we can use df.show() to display the data.
df.show(1)
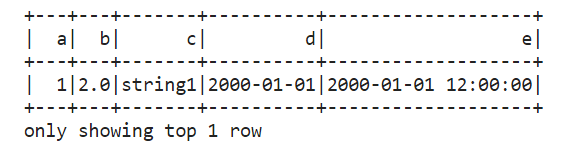
The basic operations of Spark DataFrame include:
- Select columns: df.select(df.c)
- Add columns: df.withColumn('upper_c', upper(df.c))
- Filter rows: df.filter(df.a == 1)
- Aggregation: df.groupby('color').avg()
- User-defined functions (UDF), etc.
We can also convert Spark DataFrame to Python DataFrame using df.toPandas(), which allows us to use related methods directly. We can also convert Python DataFrame to Spark DataFrame.
df = pd.DataFrame([["jack",23], ["tony", 34]], columns = ["name", "age"])
df_values = df.values.tolist()
df_columns = list(df.columns)
spark_df = spark.createDataFrame(df_values, df_columns)
As Spark DataFrame and Spark SQL share the same execution engine, we can register Spark DataFrame as a table and use SQL for logical operations.
df.createOrReplaceTempView("tableA")
df2 = spark.sql("SELECT count(*) from tableA")
#store the calculation results
df2.write.csv('data.csv', header=True)
df2.show()
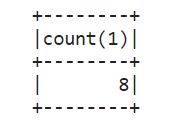
With it, we can join data using SQL (replacing Pig join functionality) and perform complex SQL logic (similar to Hive SQL) and store the final calculation results in different data formats (csv, parquet, etc.). It can be said that Spark provides us with a more complete and easy-to-use framework.
Spark DataFrame has many other APIs, but I don't have much contact with them at work, so I won't go into too much detail here. When needed, it is recommended to check the official documentation.
3 Summary¶
In the Hadoop ecosystem, Spark and PySpark provide us with a very powerful set of tools. We don't need to worry about how MapReduce is actually executed at the low level. We only need to use simple PySpark syntax or even common SQL language to flexibly and freely operate underlying data.