Crawl and download PDF files with unchanged URLs¶
Info
Author: Void, published on 2021-07-01, reading time: about 4 minutes, WeChat official account article link:
1 Introduction¶
To better sell insurance (as required by my mentor), we need to download PDF files disclosed by insurance companies on the official website of China Insurance Industry Association. There are many insurance companies, and each has many annual PDF disclosures. At the same time, miraculously, no matter how you click on the page, the URL of the webpage remains unchanged. In order to refuse to be a manual crawler, we once again try to use Python to help us efficiently and automatically download these PDF files.
2 Specific steps¶
We open the website of the China Insurance Industry Association and click on different subjects, such as the annual information disclosure of insurance companies, and we find that the URL of the page has not changed. At this time, please don't doubt your own eyes or smash the computer. We should reasonably suspect that the page has adopted some asynchronous request (Ajax ) approach. At this time, we need to find the page that sends the real request. We open the developer tools, check ALL in Network, clear it, and then click on the subject we want to select, such as related party transactions combined disclosure. Miraculously, a new URL is marked in the red box, is this the OnePiece we really want to find?
http://icid.iachina.cn/ICID/front/leafColComType.do?columnid=2016072012158397
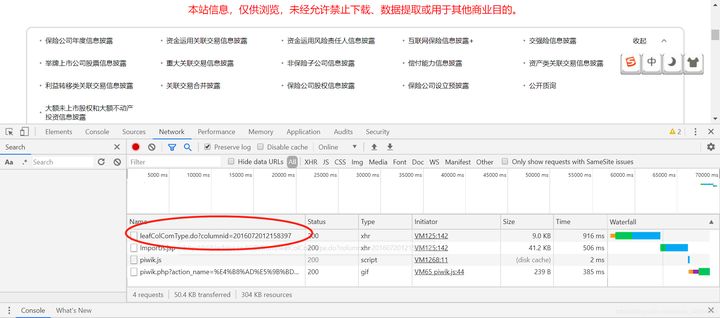
We enter this URL. Oops, this is just a website that looks similar to the previous one but is uglier.
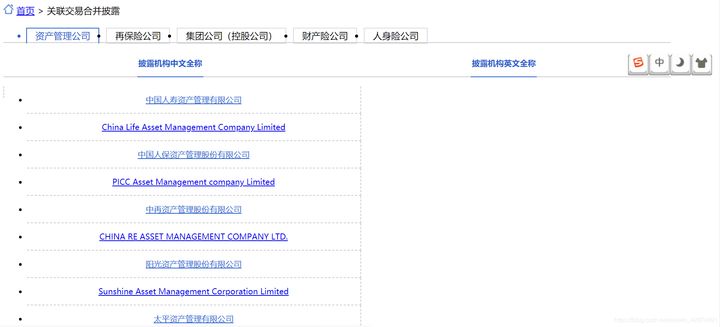
We give up and click on the first insurance company: China Life Asset Management Co., Ltd. Similarly, we found that the URL did not change. We "give up" and observe its XHR by the same operation. We found that the URL has changed again:
http://icid.iachina.cn/ICID/front/getCompanyInfos.do?columnid=2016072012158397&comCode=GSZC&attr=01
It seems that things have turned around. We found that we only need to assign the abbreviations of all insurance companies to comCode. The next step is to get the abbreviations of all insurance companies. We use "select an element" in the previous page, that is
http://icid.iachina.cn/ICID/front/leafColComType.do?columnid=2016072012158397
to inspect the name of each insurance company and found that its abbreviation is stored in the id of control "a". Therefore, we can get the abbreviations of all insurance companies by traversing, and bring them into comCode. Taking China Life Asset (GSZC) as an example, we enter the new website:

Each PDF is the result we want to get in the end. We click on an announcement and check its XHR in the same way.
http://icid.iachina.cn/front/infoDetail.do?informationno=2020012109398975
The next step is to get informationno, which is located in the id of control "a" on this page. We enter this URL. The last step is to get the PDF of China Life Asset for this annual announcement. After clicking on the announcement, we can see that the URL is
http://icid.iachina.cn/ICID/files/piluxinxi/pdf/viewer.html?file=8f993c5a-1c1c-4f91-a8a5-7fad85a14616.PDF
The file name also exists in the id of control "a" on the previous page. It should be noted that this is a viewer mode, we only need the original PDF, so change to the following URL.
http://icid.iachina.cn/ICID/files/piluxinxi/pdf/8f993c5a-1c1c-4f91-a8a5-7fad85a14616.PDF
We successfully obtained the final PDF like opening a nest of dolls. The next step is to download it with Python. We only need to write a few simple loops, click to run the program, and then open Dota2, during which time Python has downloaded nearly 1 GB of PDF files for us.
3 Summary¶
We often encounter requests that need mechanical and repetitive operations. At this time, implementing with a program is often an efficient and labor-saving choice. In this example, we successfully downloaded a large number of PDF files we needed using Python. Due to the different structures of different websites, the website of China Insurance Industry Association uses an asynchronous loading method, which causes the URL of the page to remain unchanged. We successfully found the real request sent through the developer tools.
4 Code¶
The final code is organized as follows:
from bs4 import BeautifulSoup
import requests
import time
from tqdm import tqdm
import os
header={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0"}
url="http://icid.iachina.cn/front/leafColComType.do?columnid=2016072012158397"
response=requests.get(url,headers=header)
response.encoding='GBK'
soup=BeautifulSoup(response.text,'lxml')
data=soup.select('a')
n=[]
for i in data:
try:
n.append(i.attrs['id'])
except:
continue
for z in tqdm(n):
url="http://icid.iachina.cn/front/getCompanyInfos.do?columnid=2016072012158397&comCode={}&attr=01#".format(z)
response=requests.get(url,headers=header)
response.encoding='GBK'
soup=BeautifulSoup(response.text,'lxml')
data=soup.select('a')
l=[]
name=[]
for i in data:
try:
l.append(i.attrs['id'])
name.append(i.text)
except:
continue
l=l[:-1]
name=name[:-1]
for j in range(len(l)):
url="http://icid.iachina.cn/front/infoDetail.do?informationno={}".format(l[j])
response=requests.get(url,headers=header)
response.encoding='GBK'
soup=BeautifulSoup(response.text,'lxml')
data=soup.select('a')
link=data[1].attrs['id']
url="http://icid.iachina.cn/files/piluxinxi/pdf/{}".format(link)
response=requests.get(url,headers=header)
pdf = response.content
#write pdf
c=0
with open(r"C:\Users\admin\Desktop\关联\auto\{}.pdf".format(name[j]),'wb') as f:
f.write(pdf)
while os.path.getsize(r'C:\Users\admin\Desktop\关联\auto\{}.pdf'.format(name[j]))==0:
time.sleep(3)
url="http://icid.iachina.cn/files/piluxinxi/pdf/{}".format(link)
response=requests.get(url,headers=header)
pdf = response.content
with open(r"C:\Users\admin\Desktop\关联\auto\{}.pdf".format(name[j]),'wb') as f:
f.write(pdf)
c+=1
if c>=5:
break