Introduction to Apache Projects¶
Info
Author: Void, Published on December 25, 2021, Reading Time: About 6 Minutes, WeChat Official Account Article Link:
1. Preface¶
The Apache Software Foundation is a non-profit organization that provides support for operating open-source software projects. From a community of developers exchanging technical information in the beginning, Apache has become the world's largest open-source software foundation. Its various open-source software has served various industries around the world and entered into our daily life.
This article will briefly introduce some common Apache Top-level projects. The so-called top-level projects refer to graduating projects that have been incubated and meet certain quality requirements.
2. Airflow¶
Apache Airflow is a platform for scheduling and monitoring data pipeline workflows written in Python. It builds workflows through DAG (Directed Acyclic Graph). Through visualization on the web page, we can intuitively observe dependencies, monitor progress, and manage tasks.
3. Arrow¶
Apache Arrow is a cross-platform format for memory data processing and exchanges. It uses columnar storage and reduces communication overhead between systems because different platforms use the same memory format.
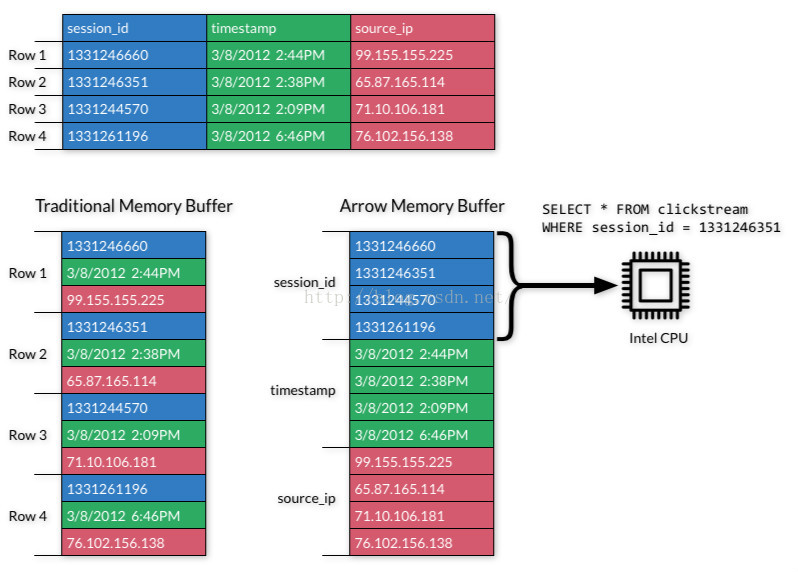
Using Python to read large data files often takes a long time. We can use Pyarrow to greatly reduce this time-consuming process. Feather is a type of data format included in the Apache Arrow project, and we can store and read Dataframe as a feather file.
df.to_feather(path, compression, compression_level)
df = pd.read_feather('data.feather')
4. Avro¶
Apache Avro is a serialization format that is independent of programming languages. It can be combined with the Hadoop ecosystem, and Hive table definitions can also be directly declared with Avro schema.
5. Flink¶
Apache Flink is a stream processing framework. It executes arbitrary stream data programs in data parallelism and pipeline modes. It is worth mentioning that in 2019, Alibaba acquired Flink for US$100 million. This shows that Flink meets Alibaba's needs for complex real-time computing very well.
6. Hadoop¶
Apache Hadoop is a distributed system infrastructure and is one of today's indispensable big data ecosystems. The core design of the Hadoop framework is HDFS (Hadoop Distributed FileSystem) and MapReduce. HDFS provides storage for massive data, and MapReduce provides computing for massive data.
7. Hive¶
Apache Hive is a distributed data warehouse system based on Hadoop. It can translate SQL into MapReduce programs and send them to the calculation engine for computation. Hive is active in various Internet companies, and it is also an old friend that accompanies me every day.
8. HTTP Server¶
Apache HTTP Server is the most popular web server today. It does not need much introduction; the Apache Foundation also originated from this project.
9. Kafka¶
Apache Kafka is a high-throughput distributed publish-subscribe messaging system that can efficiently process action stream data.
10. Pig¶
Apache Pig is also based on the Hadoop ecosystem, and it provides a class SQL language called Pig Latin, which will convert SQL-like data analysis requests into a series of optimized MapReduce operations.
11. Spark¶
Apache Spark is another famous project. It provides a unified data processing platform. It has a general parallel framework similar to Hadoop MapReduce, but with some optimizations. It includes Spark Core, Spark SQL, Spark Streaming, MLlib, etc.
12. Tez¶
Apache Tez constructs an application framework by allowing complex DAG tasks to run in projects such as Apache Hive and Apache Pig.
13. ZooKeeper¶
Apache ZooKeeper is an animal administrator for Hadoop (elephant), Hive (bee), and Pig (pig). It is a distributed, open-source program coordination service with main features including configuration management, name services, distributed locks, and cluster management.
14. Conclusion¶
It can be seen that the Apache Foundation has incubated many famous projects, and these projects are used in various software, serving all aspects of our lives. Thank you for the contribution of these open source giants!