TabNet小介¶
1 前言¶
对于表格型数据,树模型(LightGBM,XGBoost)往往能有不错的表现。可能的原因有:
- 容易构造或已经有丰富的特征库。
- 树模型的决策流形(decision manifolds)是超平面边界的(可以理解为一刀一刀切出来的),对此类问题表现较好。
由于对于某些任务,NN模型(Neural Network Model)的表现只能算差强人意,而我们又需要有NN模型参与最后的模型ensemble,机智的研究者们为此设计出了类似树模型的NN模型。本文将介绍的就是此类模型:TabNet。
2 用NN构造决策树¶
决策树我们可能已经比较熟悉了,它的决策边界可见如下简单示例:
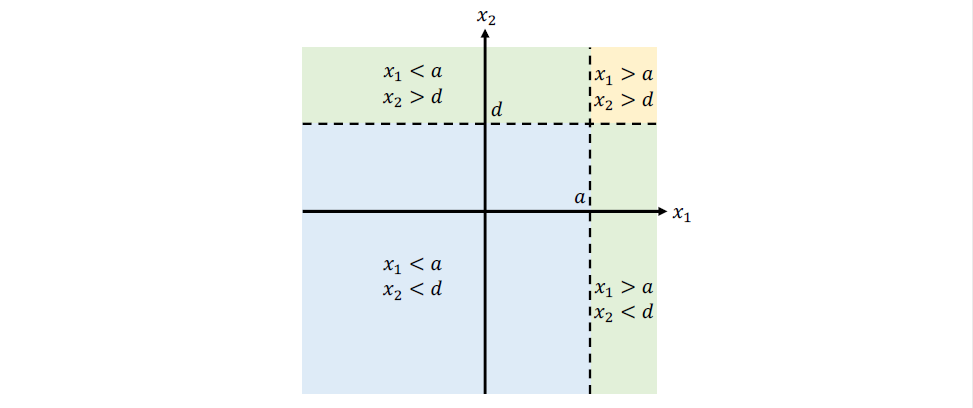
两个特征x1,x2分别以阈值a,d进行划分,将数据集划分成4块。那么NN如何能模拟这一过程呢?
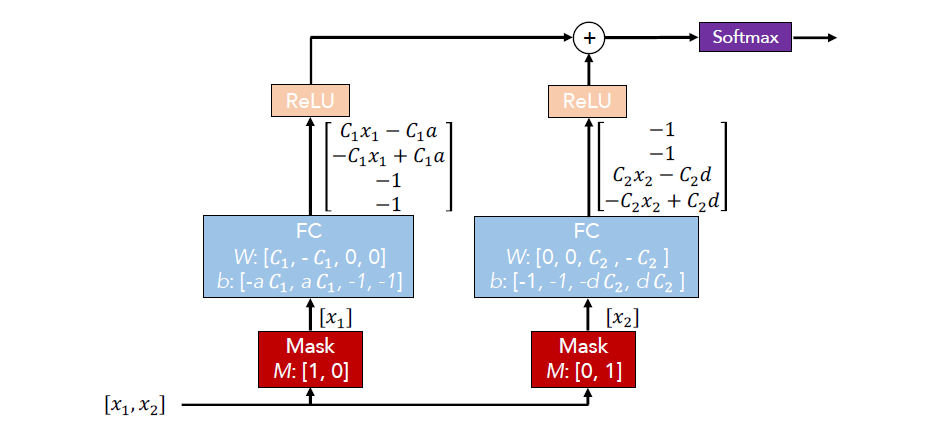
可以看到,模型的输入同样是x1,x2两个特征,首先通过Mask层将它们分别筛选出来,因为树模型在构造的过程中,也是独立的在每一步选择分裂增益最大的那一个特征。
接着,两个特征分别接了一个设计好权重和bias的全连接层,并通过RELU激活函数输出。
由于RELU(x)在x>0时,即为x,小于0时,为0。那么对于x1来说,当x1>a时,最终输出为[c1x1-c1a,0,0,0],若x1<a,输出为[0,-c1x1+c1a,0,0]。可以看到这里相当于以a为阈值,进行划分。这里的两个-1维度其实是用来对齐填充维度的。
最终,我们把不同特征的输出加起来,并作用softmax,得到输出向量,如[0.1,0.5,0.3,0.3]。其中,每一维代表某个条件成立时,对最终决策的影响权重。如0.1代表x1>a对最终决策的影响权重只有10%。值得一提的是,模型参数的更新仍然采用的是反向传播,并没有涉及到增益的计算。
3 TabNet结构¶
TabNet针对上述简单结构做了改进。
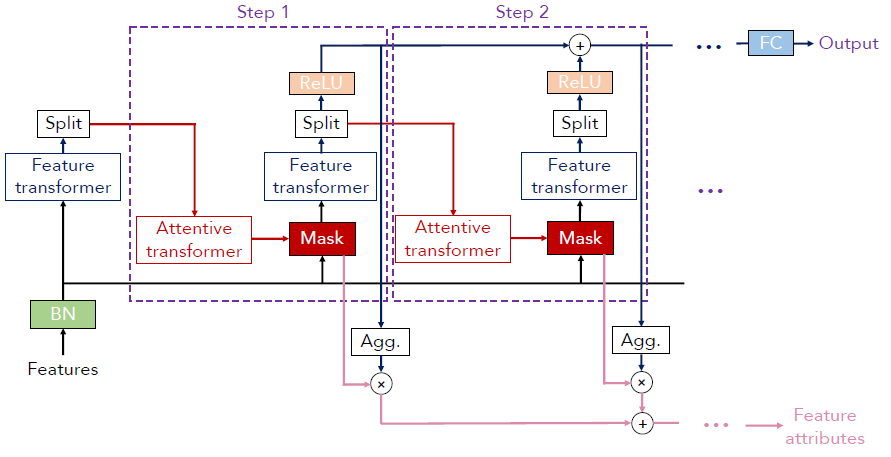
特征先通过一个BN(batch normalization)层,接着通过Feature transformer层。这一层的作用和之前所述的全连接层类似,都是在做特征计算,它的结构如下:
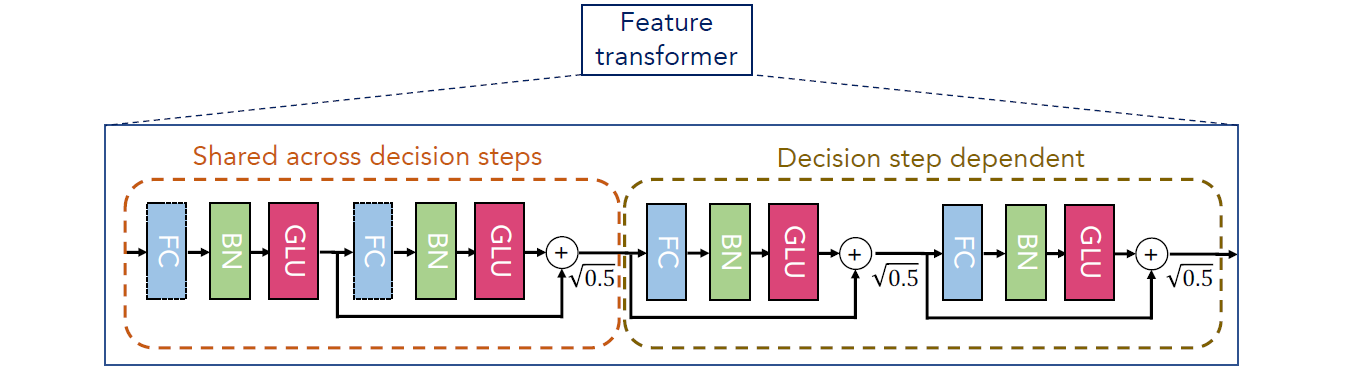
它有两大部分,所有step共享的部分以及每个step独有的决策部分,其中的小结构都是残差连接的由全连接层(FC,Fully Connected Layer),BN层以及用来做特征选择的GLU(Gated Linear Unit)构成的小结构。接着split后(选择部分特征),通过attentive transformer进行特征选择(主要通过sparsemax将某些特征置为0)。直观上可以理解为之前被多个steps选中的特征就不应该被模型选择了。最终生成运用于下个step的Mask矩阵。
右下角的Feature attribute刻画的是则是变量的全局重要性。
4 总结¶
以上就是TabNet的基本结构,它通过加性模型以及注意力机制实现了instance-wise的特征选择,兼顾了树模型以及NN的优点。在面对表格型数据的问题中,不妨尝试一下看看效果如何。
关于TabNet的理论理解有解释不到位的也可以看看原文或是知乎大神的文章。
%20-%20Tail%20Pic.png)